오랜만에 옮기면서 보니깐 이때 당시에 정말 모르는 게 많았던 것 같다. 물론 맞다. 딥러닝 자체를 대학원 가서 처음 배우다시피 해서 잘 몰랐다. 딥러닝을 전공으로 한 것도 후회를 많이 했었다. 지금도 후회하고 있다. 딴 거 할걸..
아직까지도 딥러닝 논문들은 적용해보면 안 되는 것들이 태반이고 맨날 비슷한 논문만 계속 나온다. 학회에 낼 수 있는 연구를 하기보다는 이 방법 저 방법 적용해 보는 내 상황에서는 모든 논문들이 구라 같다. 그렇지만 잘하는 사람들은 항상 잘 찾아내서 성능향상을 만들어 낸다. 아직은 내 내공이 많이 부족하다고 느낀다. 그렇지만 열정을 다 잃어버려서 큰일이다.

FDA : Fourier Domain Adaptation for semantic segmentation (CVPR 2020)
Summary
Problem
Unsupervised domain adaptation을 하고싶다. 근데 우리가 새로운 사실을 알아냈다. 어떤 경우에는 low-level statics의 변화로 perceptually insignificant하지만 model의 성능을 확연히 떨어트리는 경우가 있다.
Inspiration
domain이라는게 주파수와 관련이 높아 보이고 관련 논문도 있다. 2019 ICCV에 wavelet transform에 관련된 논문도 있음.
low level spectrum은 high level semantics에 영향을 주지 않고 크게 바뀔 수 있다. 예를 들어서 사람이나 차를 인식한다고 하면 찍는 카메라, 조명 같은 low level의 노이즈나 변화가 semantic information을 바꾸지 않는다는 것이다. 그러나 이런 변화는 spectrum에는 큰 영향을 준다. 근데 이런 low level에서 다양한 데이터를 모델에게 보여주지 않는다면 모델이 generalize하는데 실패할 것이다.
이 논문의 저자들은 task에 따라 다르겠지만 task를 수행하는데 크게 영향을 미치지 않는 부분들을 다양하게 만들어서 모델의 입력으로 넣어주면 모델의 성능이 올라갈 것이다라고 생각을 했다. 그래서 categorical interpretation같은 경우는 semantic한 걸 구분하는 task니깐 low level에서 다양성을 주면 semantic한 정보는 바뀌지 않으면서 데이터의 다양성은 올라갈 것이라고 생각했고, 예상이 어느 정도 맞았다.
이 사람들의 콘셉트는 low level의 nuisance(성가신 것들, noise, non linear function)를 learning하기전에 없애보자는 생각임. non linear constrast change(gray scaling) 같은 것들은 low level에서 색깔과 밝기를 건드리지만 이걸 model안에서 하지 않고 애초에 data preprocessing과정에서 하는 것처럼 FFT도 러닝 하기 전에 해주자. 그러면 model이 generalize하지 않은 부분을 보완할 수 있다. 이런 방법은 이상적인 기준이나 방법이 없는 거 같으니 fourier transform을 한번 적용해 보자.
Solution
FFT를 하고 나면 amplitude, phase map을 얻을 수 있는데 source, target 이미지 amplitude map의 low frequency영역을 간단하게 교체하는 것만으로도 UDA를 적용한 semantic segmentation에서 SOTA성능이 나온다.
Main contribution
- semantic segmentation의 성능을 높일 수 있는 simple UDA method without learning model. 그러나 segmentation task에만 적용될 수 있는 건 아니다.
Architecture

기본 구조는 간단함. UDA자체는 FFT로 frequency 이미지를 생성하고, target과 source amplitude 이미지의 low frequency를 교체해 주면 DA된 이미지가 나오는데 저 이미지로 segmentation을 하면 성능이 향상된다.
사용한 segmentation model
2개의 segmentation model을 사용했다. 그렇게까지 최신모델은 아니고, 둘 다 pretrain 되지 않은 모델을 사용함.
- DeepLabV2 with a ResNet101 backbone(2017)
- ASPP 모듈을 사용하여 multi-scale object를 segment할 수 있음을 강조
- DCNN으로 만든 score map을 Bi-linear Interpolation을 통해 키우고 CRF로 디테일을 살린다는 면에서 Deeplabv1


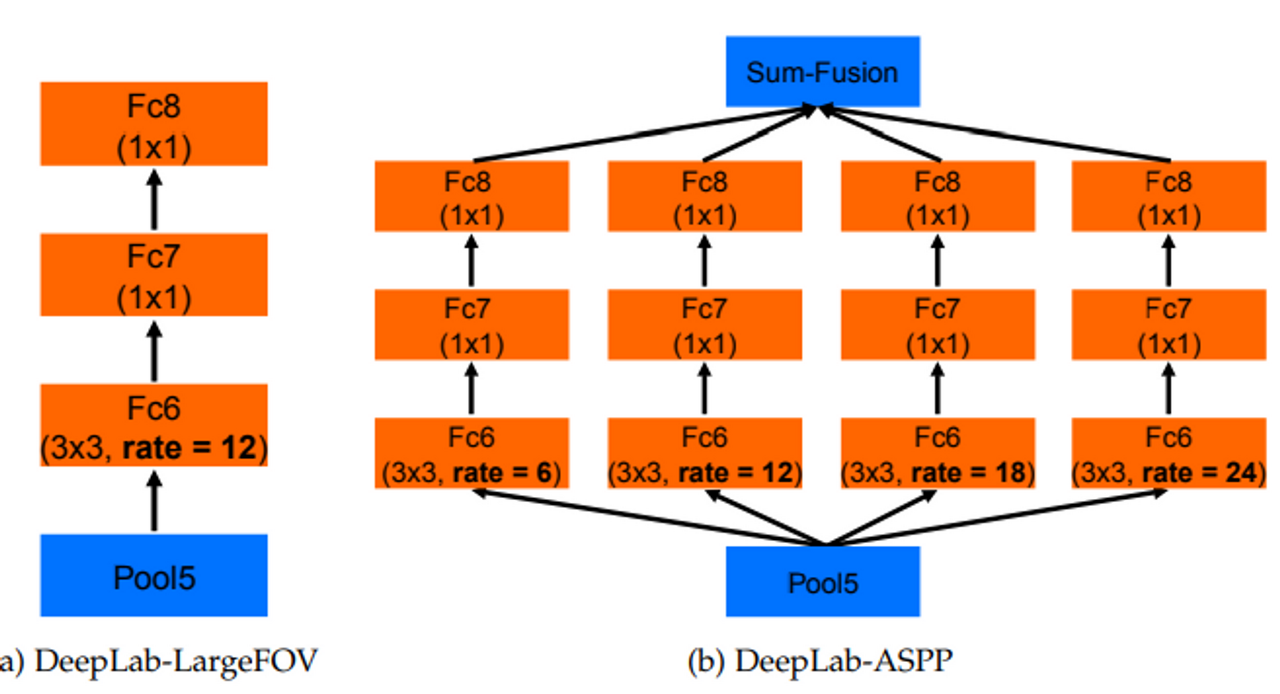


- FCN-8s with a VGG16 backbone (2015)
- 기존 classifier → segmentation network로 사용한 방법
- FC layer → 1X1 convolution layer로 바꿔서 사용했다.


Loss function
1. segmentation loss

- cross entropy 사용. 각 pixel마다 classification.
- source의 label을 사용한다.
2. entropy minimization loss

- target이미지를 모델에 넣었을 때 class clustering을 위한 loss. target은 label이 없으니깐 어떤 클래스인지는 몰라도 clustering이 잘되도록 학습하자는 의미로 넣은 것 같음. 그 clustering하는 방법이 entropy minimization loss를 사용하는 것이고, 이 방법이 low entropy에서는 비효율적이니깐 weighting function을 추가적으로 사용했다.
- shanon entropy를 minimization하도록 하는데 arbitrary threshold를 줘서 penalty를 주는 건 low entropy에서는 비효율 적이니깐 charbonnier penalty를 줘서 좀 더 스무스하게? high entropy가 나오는 걸 방지했다.
- 이 loss에 대한 설명. 아직 이해 안 감. → Since FDA aligns the two domains, UDA becomes a semisupervised learning (SSL) problem. The key to SSL is the regularization model. We use as a criterion a penalty for the decision boundary to cross clusters in the unlabeled space.
- This can be achieved, assuming class separation, by penalizing the decision boundary traversing regions densely populated by data points, which can be done by minimizing the prediction entropy on the target images. However, as noted in [45], this is ineffective in regions with low entropy. Instead of placing an arbitrary threshold on which pixels to apply the penalty to, we use a robust weighting function for entropy minimization.
- where $ρ(x) = (x^2 + 0.001^2)^η$ is the Charbonnier penalty function [2]. It penalizes high entropy predictions more than the low entropy ones for η > 0.5

3. pseudo label segmentation loss (self supervised loss)

pseudo label은 $\beta$ 를 바꿔서 M(이 실험에서 M=3) 개의 모델을 사용해서 나온 class prediction을 평균 때려서 pseudo label로 사용했다.
4. total loss

Pseudo label을 만들기 위한 M개의 모델은 위의 loss function을 사용.
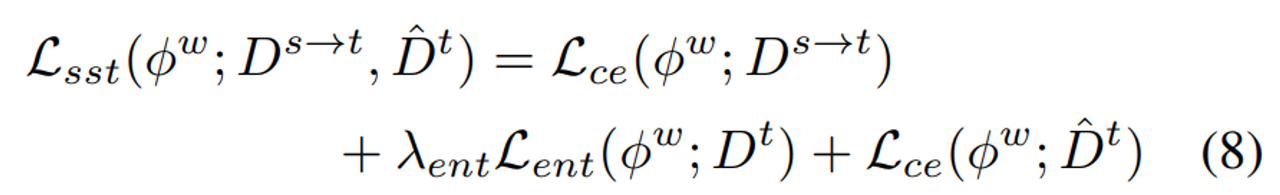
최종적으로 사용할 모델은 3개의 loss function을 다 사용. 이런 방식을 mean prediction of different segmentation networks Multi-band Transfer (MBT)라고 하는 것 같다.
Interesting point of paper
- adversarial learning이 low-level의 다양성에 general하지 않다.
- However, the fact that such a simple method outperforms sophisticated adversarial learning suggests that these models are not effective at managing low-level nuisance variability.
- 예를 들면 색깔이 다르다 던 지, 밝기의 차이 등을 고려하기 위해서는 새로운 데이터를 넣어줘야 한다. 이게 하기 싫으니깐 low level에서 건드려보자 라는 아이디어를 제안했다. 그러면 day ↔ night change 같은 task에도 적용해 볼 수 있을 듯함. (근데 예상되는 문제점은 가로등 같은 경우에는 밤에는 불이 켜진다. 이런 차이도 low level에서 감지할 수 있을까?)
Strength
Weakness
Appendix
- charbonnier penalty
- 어떤 문제에 constraint가 있는데 그 constraint를 만족하지 못하는 경우가 생기므로 그런 경우에는 페널티를 주자! 할 때 사용함.
- The goal of penalty functions is to convert constrained problems into unconstrained problems by introducing an artificial penalty for violating the constraint.
- mean teacher
- multi band transfer (MBT)
- covariate shift
- 이게 domain 차이가 있을 때 모델의 성능이 떨어지는 가장 큰 이유.
- entropy minimization
'Deep learning > Paper review' 카테고리의 다른 글
| Unsupervised PixelDA paper review (CVPR 2017) (0) | 2023.06.24 |
|---|---|
| Pix2Pix paper review (CVRP2017) (0) | 2023.06.24 |
| SinGAN paper review (ICCV 2019) (0) | 2023.06.24 |
| CycleGAN paper review (ICCV 2017) (0) | 2023.06.23 |



