반응형

예전에 석사 초창기에 읽었던 논문 리뷰한 내용들을 여기에 다시 적어본다. 리뷰도 개판이고 핵심들을 진짜 잘 못 정리했던 것 같지만 썩히기에는 아까워서 티스토리에 다시 올려본다. 예전에는 노션에 정리를 했었는데 다시 백업해와서 차곡차곡 티스토리에 옮겨적어야겠다.
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks (ICCV 2017)
Summary
- Problem
- image translation을 하는데 보통 paired dataset이 필요한데 이런 데이터를 구하기가 힘든 경우가 많다. photo → artistic picture를 예로 들 수 있다. 그리고 그냥 pair가 아닌 데이터 사이에도 domain을 변화시키고 싶을 때 사용할 수 있는 방법이 필요하다.
- Inspiration
- adversarial autoencoder가 x → latent representation → G(x)의 구조를 가지는데 latent representation의 distribution을 arbitrary target domain과 match시키는데서 아이디어를 받았음.
- 그러면 GAN이 이미지나 도메인의 distribution을 잘 학습하니깐 encoder → forward GAN, decoder →backward GAN으로 만든다면 잘 되지 않을까?라고 생각한거 같음.
- Solution
- 2개의 GAN을 써서 encoder, decoder를 구성해보자. x → encoder → y → decoder → x,
- y → decoder → x → encoder → y가 되도록 network를 구성한다면 y의 distribution을 더 잘 학습할 것이다. 그러면 2개의 도메인을 자유롭게 왔다갔다 할수도 있다.
- autoencoder를 GAN으로 재해석을 했다고 볼 수도 있고, mapping의 성능을 높일 때 inverse mapping의 성능도 높인다면 효과가 있다고도 볼 수 있다.
- Main contribution
- novel architecture : inverse연산이 forward연산의 성능을 높일 수 있다는 생각과 그 architecture.
- unpaired dataset에도 돌아간다. pix2pix는 paired dataset으로 학습을 시켰다.
- Architecture
- Generator
- 3개의 convolution, residual block(6 or 9), 2 fractionally-strided convolution (stride = 1/2), convolution(feature → RGB) + instance norm
- Discriminator
- 70 X 70 patchGAN
- Generator

반응형
- Loss fuction

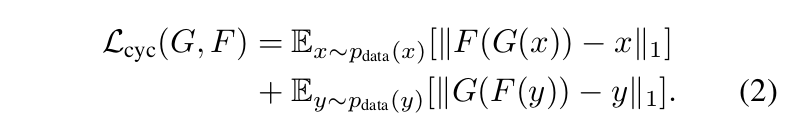


- Interesting point of paper
- G와 F의 상호 보완적인 구조를 사용하여 cycle consistent라는 property를 활용했다.
- space of possible mapping을 줄이기 위해서 cycle consistent property를 추가했다.
- training detail
- 다른 논문이 밝혀낸거를 사용한거지만 처음 봄.
- Training을 stabilize하기 위해서 negative log likelihood objective → least-squares loss로 변경. stability뿐만 아니라 결과의 퀄리티도 더 좋다.
- Model oscillation을 줄이기 위해서 discriminator를 업데이트 시킬때 한장 한장마다 update를 하는게 아니라 여러장이 쌓이면 그때 업데이트 하는걸로 함. (history of generated images) mini batch SGD랑 비슷한 느낌. 타당해 보이는 방법.
- 한쪽에만 cycle consistent loss를 주는 경우 mode collapse가 자주 발생했고, 특히 mapping 방향이 사라졌다.
- pix2pix처럼 identity maping loss(input과 output간의 L1 norm)를 사용하니깐 color, intensity distribution이 많이 비슷해졌다.
- Introduction
paired dataset에 supervised learning으로 돌리는 거는 많이 있다.- D. Eigen and R. Fergus. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In ICCV, 2015.
- A. Hertzmann, C. E. Jacobs, N. Oliver, B. Curless, and D. H. Salesin. Image analogies. In SIGGRAPH, 2001.
- P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. In CVPR, 2017.
- J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In ECCV, 2016.
- Y. Shih, S. Paris, F. Durand, and W. T. Freeman. Data-driven hallucination of different times of day from a single outdoor photo.
- Y. Shih, S. Paris, F. Durand, and W. T. Freeman. Data-driven hallucination of different times of day from a single outdoor photo.
- Related work
- GAN
- generation, editing, representation learning, text2image, inpainting, future prediction, etc. 안쓰는데가 없음.
- Image-to-Image translation
- 2001년 image anolgies라는 논문에서 부터 시작한다 - non parametric texture model.
- 최근에는 딥러닝 써서 parametric translation function을 만듦. cycle gan은 pix2pix2기반으로 연구했따. paired image 가지고 연구가 많이 됐는데 우리는 unpaired image 사용함.
- Unpaired Image-to-Image translation
- 2개의 도메인 사이를 연결하는 목적을 가진 task. bayesian framework(markov random field와 likelihood를 사용한 방법)이 2003년에 연구되었고, 최근에는 coGAN과 cross modal scene network는 weight sharing stategy로 domain 사이의 representation을 학습했다.
- VAE와 GAN을 적절히 섞어서 사용하는 방법도 있음. content는 같게, style은 다르게에 초점을 맞춘 GAN을 사용한 방법도 있다. constraint를 줄 때 space를 나눠서 줄 수 있는데 class label, pixel, feature space로 3가지 정도로 space를 구분할 수 있다.
- Cycle-consistency
- 이 structured data를 regularize하는 아이디어는 오래 전부터 있었다. 예를 들어서 visual tracking에서 forward-backward consistency를 사용한다.
- Neural style transfer
- pre trained deep feature의 gram matrix statistics를 사용해서 content와 style을 합성하는 task. 우리가 하고싶은거랑 쫌 다른거는 이거는 1:1로 style을 전달하는 거라면 이 논문에서 하고 싶은거는 다 : 다로 mapping을 시키는 것. high-level-appearance를 학습해서 여러 task에 써먹을 수 있다. style transfer가 잘 동작하지 않는 painting → photo, object transfiguration 같은 task에도 더 잘 동작한다.
- GAN
Strength
- novel architecture
- a llitle analysis
Weakness
- cycle consistency가 각각의 mapping에 효과가 있는가?? 하는 의문이 듦.
- consistent loss가 효과가 있기 위해서는 이미 어느정도 실제 데이터 분포와 생성된 데이터의 분포가 비슷해야 효과가 있을 것 같다는 생각이 듦.
- color 나 texture같은 거는 변환이 잘되는데 geometric change는 변환이 잘안됨. 예를 들어서 고양이→강아지 하면 그냥 변화가 없음.
- 이거는 geometric change + different label 문제이지 않을 까 싶음. 보여준 실험중에 label이 다른경우는 못봤음.
- label이 섞이는 경우나 바뀌는 경우가 생김.
Appendix
- bi-jection
- 전단사 함수. 중복없이 일대일 대응이 되는 함수, 이 논문에서는 F와 G가 bijection이 되어야한다고 말함.
- perceptual loss
- image transformation task에 사용할 목적으로 만들어진 loss, SR task에도 사용됨. 이전에는 output과 GT간의 per-pixel loss를 사용했다. per-pixel loss는 perceptual difference를 측정하지 못한다. 그래서 high level feature 기반의 loss를 새로 정의함
- perceptual loss = feature(content) loss + style loss
- feature loss(content loss) : 이미지 사이의 유사도를 측정하기 위해서 2개의 이미지가 pretrained neural network를 거치면서 나오는 feature representation을 euclidean distance를 사용해서 loss를 측정함.
- style loss : 아직은 잘 모르겠지만 gram matrix로 정의.
- Generating images with perceptual similarity metrics based on deep networks. NIPS, 2016.
- Perceptual losses for real-time style transfer and super-resolution. ECCV, 2016.
- identity mapping loss
- A와 B가 같아지도록 만드는 loss, auto encoder에서 input과 output 이미지 사이의 L1 norm으로 생각하면 됨.
- mode collapse
- GAN이 generator와 discriminator가 번갈아 가면서 학습을 진행하기 때문에 generator 입장에서는 discriminator가 가장 구분을 잘 못하는 1개의 sample만 계속 내보면 된다. 이런 식으로 목적과 다르게 학습이 되는걸 mode collapse라고 한다.
반응형
'Deep learning > Paper review' 카테고리의 다른 글
| FDA paper review (CVPR 2020) (0) | 2023.06.24 |
|---|---|
| Unsupervised PixelDA paper review (CVPR 2017) (0) | 2023.06.24 |
| Pix2Pix paper review (CVRP2017) (0) | 2023.06.24 |
| SinGAN paper review (ICCV 2019) (0) | 2023.06.24 |



